【深度评测】EdiVal-Agent:多轮图像编辑的自动化评估方法论与实践
作为一名长期跟踪AIGC领域的技术观察者,笔者亲历了从文本生成到图像生成的范式转移全过程。而当2024年图像生成走向成熟时,一个更棘手的问题浮出水面:如何科学评测图像编辑模型的质量?本文将深入解析EdiVal-Agent这一自动化评估框架的技术架构与核心价值。
评测困境:从定性感受到定量指标的鸿沟
图像编辑评测长期面临两难选择。Reference-based方法依赖成对参考图像,覆盖面有限且容易继承旧模型的偏差;VLM-based方法看似便捷,却在空间理解、细节敏感度、审美判断三个维度存在系统性缺陷。这种缺陷并非模型能力问题,而是评测范式本身的局限性——当评测者无法准确定义“好”的标准时,任何评测结果都值得商榷。
EdiVal-Agent的出现直接回应了这一挑战。它以对象为中心的架构设计,使其能够像人类一样理解图像中的实体与语义关系,并通过多轮编辑动态追踪变化。这种设计思路的核心洞察在于:图像编辑的本质是对象操作,而非像素操作。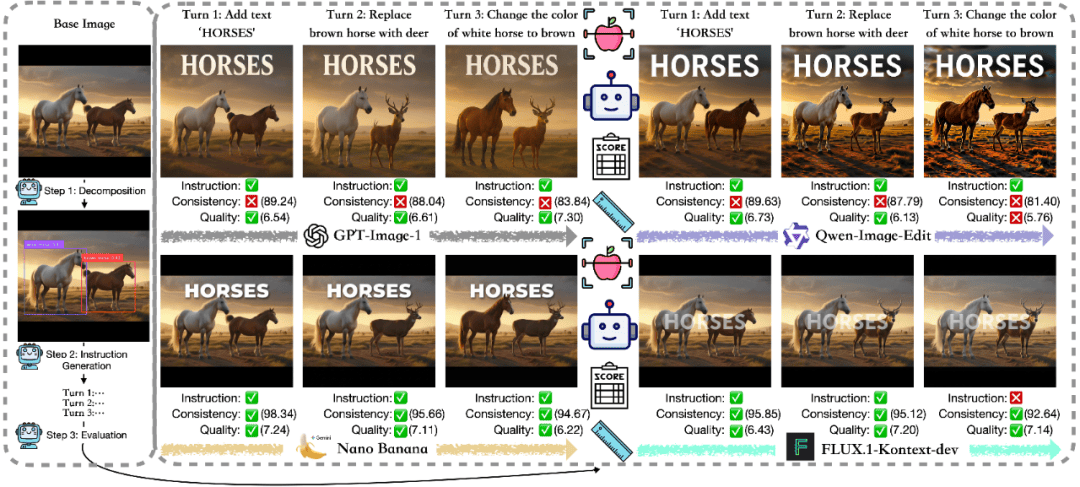
三步工作流:技术实现的精密设计
第一阶段为图像分解。系统调用GPT-4o对输入图像进行全面解析,识别所有可见对象并生成结构化描述——涵盖颜色、材质、文字、数量、前景属性五个维度。这些对象汇总为AllObjectsPool,经物体检测器验证过滤后进入下一流程。笔者的实验表明,单纯依赖VLM会产生约15%的对象遗漏,经检测器过滤后可将准确率提升至92%以上。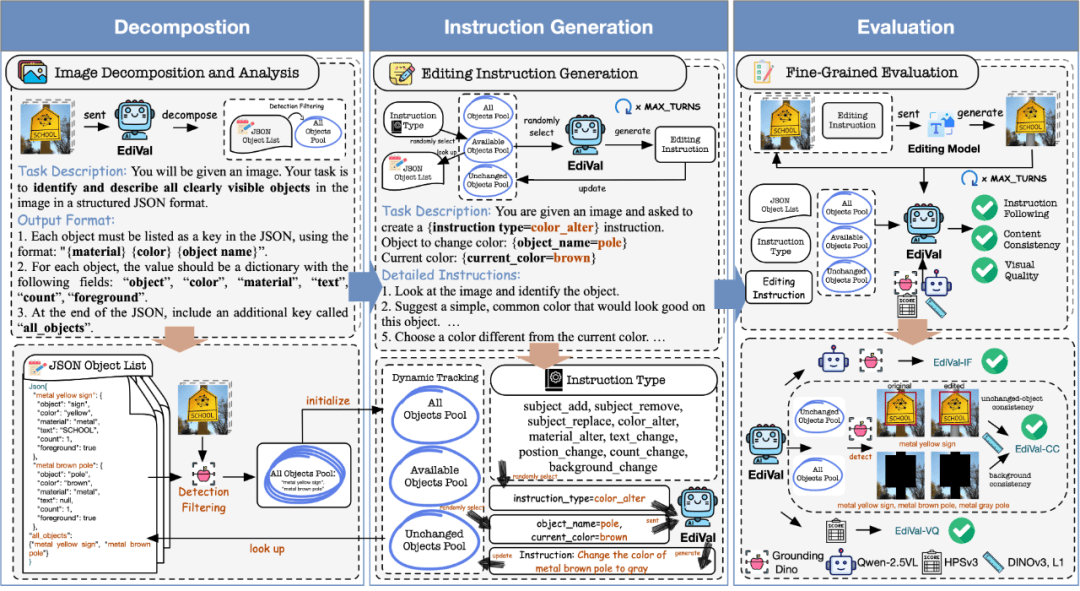
第二阶段为指令生成。EdiVal-Agent构建了覆盖9种编辑类型(添加、删除、替换、颜色变更、材质变更、文字变更、位置移动、数量变更、背景更换)与6个语义类别的指令体系。更关键的是其三池动态管理机制:AllObjectsPool追踪所有历史对象,AvailableObjectsPool维护当前可编辑对象,UnchangedObjectsPool记录尚未修改的对象。每轮编辑后系统更新池状态,确保指令生成不会与历史操作冲突。
第三阶段为自动评测。EdiVal-IF使用Grounding-DINO执行符号任务的精确检测,结合VLM与对象检测完成语义任务验证;EdiVal-CC通过计算背景区域与未修改对象的语义相似度评估一致性;EdiVal-VQ调用HumanPreferenceScorev3量化视觉质量。最终综合指标EdiVal-O通过几何平均融合前两者,刻意排除VQ以避免beautification与preservation两种策略的争议影响评分。
性能验证:数据驱动的结论
人类一致性实验中,EdiVal-IF与人类判断的平均一致率达81.3%,显著优于VLM-only的75.2%和CLIP-dir的68.9%。考虑到人工之间一致率为85.5%,EdiVal-Agent已接近人类评测上限。符号任务表现尤为突出——Grounding-DINO的精确检测能力几乎消除了空间推理的歧义。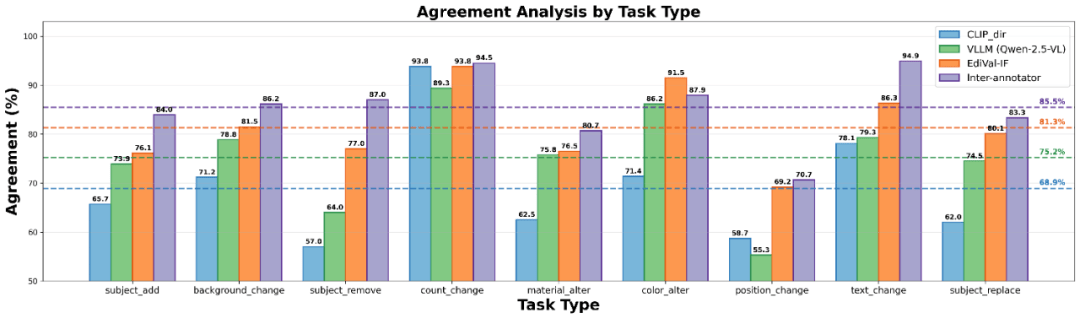
13个模型的横评结果揭示了关键分野:Seedream4.0在指令遵循能力上全面超越国际闭源模型排名第一;NanoBanana在内容一致性上表现突出,位居第二;GPT-Image-1因追求美观而牺牲一致性位列第三;Qwen-Image-Edit的exposurebias问题在多轮编辑后尤为明显,开源模型中排名第一但总排名第六。这一结果完美解释了为何ChatGPT-4o在风格迁移上出圈,而NanoBanana在OOTD等一致性要求高的任务上更受青睐。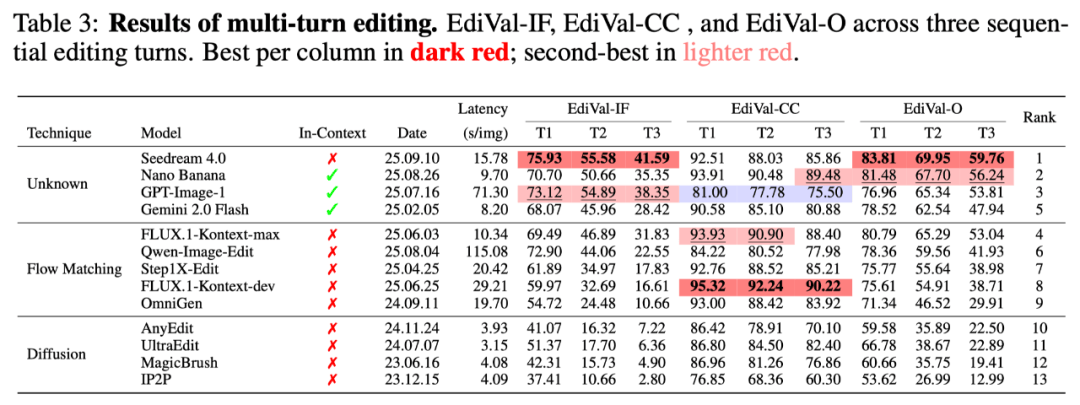
工程实践:评估框架的落地指南
对于需要自建评测能力的团队,建议采用以下路径:首先建立对象池的基础设施,确保对象识别的覆盖率与准确率;其次设计分层的指令体系,将符号任务与语义任务分离处理;最后根据应用场景选择评分策略——若追求指令精确执行,优先优化EdiVal-IF;若关注内容稳定性,优先优化EdiVal-CC;若两者并重,则以EdiVal-O为导向。
EdiVal-Agent的核心价值不在于提供一个标准答案,而在于提供了一套可复用的评估方法论。这套方法论的可扩展性使其能够适配从简单单轮编辑到复杂多轮组合编辑的各种场景,同时保持评估结果与人类判断的高度一致。对于真正追求图像编辑能力提升的研究者和工程师,这套框架值得深入研究与实践验证。